
Cancer Subtype Classifier – Demo using Gene Expression and ML
🧩 Problem Statement
In cancer genomics, identifying the cancer subtype of a tumor sample is crucial for:
- Accurate diagnosis
- Treatment planning
- Precision medicine research
However, high-dimensional RNA-seq data makes subtype classification challenging, especially across multiple cancer types.
❓ Why Are We Solving This?
Automatically classifying tumor samples based on gene expression can:
- Help researchers label or validate samples
- Support oncologists with second-opinion diagnostics
- Serve as a preprocessing layer for further mutation or survival analysis
Approach
We built a multi-class machine learning classifier that:
- Takes a tumor sample’s RNA-seq gene expression (20,531 genes)
- Predicts the primary cancer type (subtype)
- Visualizes performance, top genes, and live predictions
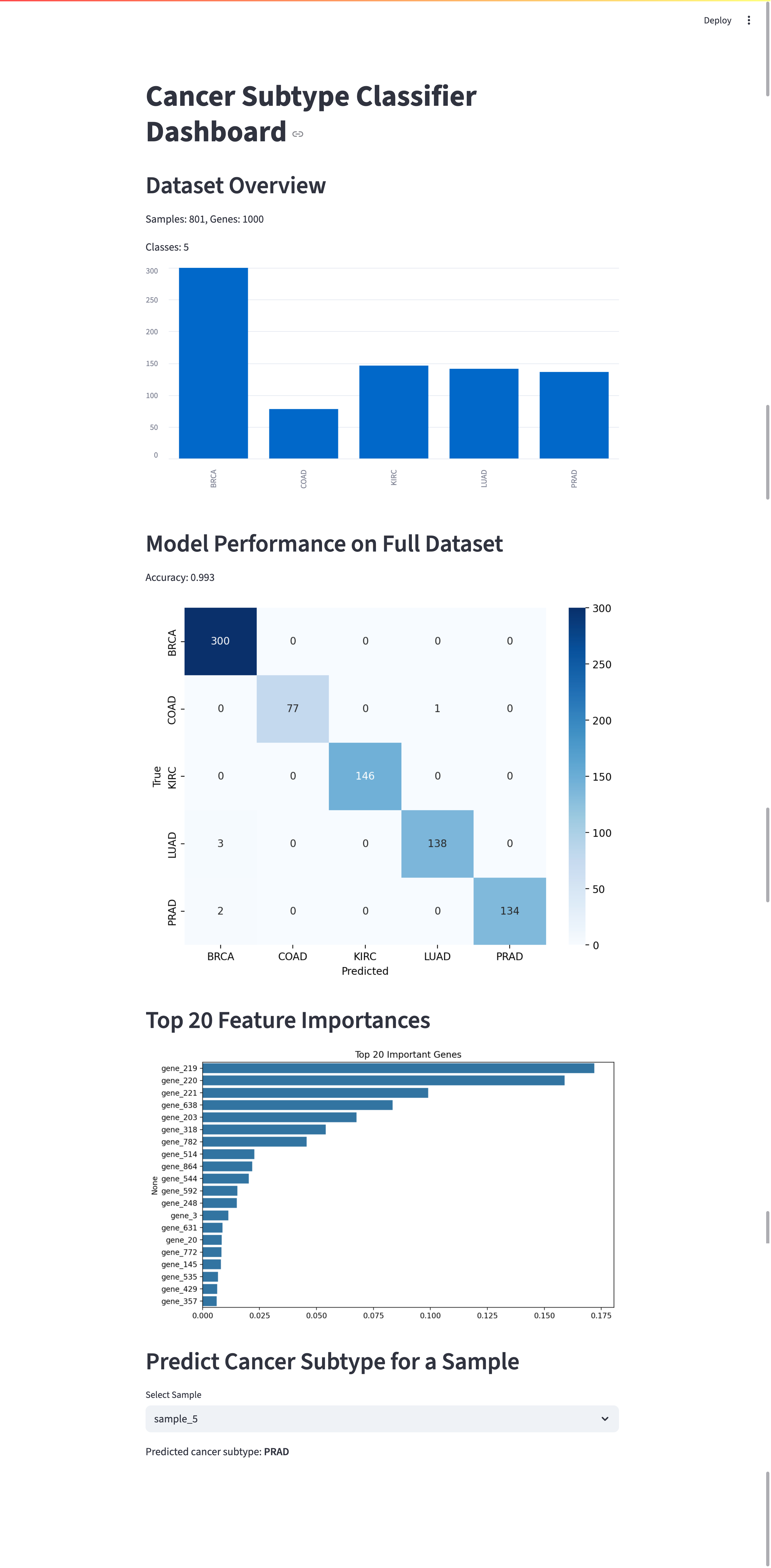
Dataset
We used the TCGA-PANCAN-HiSeq-801x20531 dataset:
- Samples: 801 tumor samples
- Genes: 20,531 (RNA-Seq HiSeq platform)
- Source: The Cancer Genome Atlas (TCGA)
- Format: CSV matrix (samples × genes) with labels
Cancer types in this pancancer set include:
BRCA– Breast invasive carcinomaCOAD– Colon adenocarcinomaLUAD– Lung adenocarcinomaKIRC– Kidney renal clear cell carcinomaHNSC– Head and neck squamous cell carcinomaOV– Ovarian serous cystadenocarcinomaTHCA– Thyroid carcinoma
…and others
Tech Stack
| Component | Tool |
|---|---|
| Machine Learning Model | XGBoost Classifier |
| Label Encoding | scikit-learn LabelEncoder |
| Pipeline | scikit-learn Pipeline |
| Dashboard UI | Streamlit |
| Data Processing | pandas, seaborn, matplotlib |
| Model Persistence | joblib |
Working
- Load
data_small.csv(trimmed gene matrix) andlabels.csv - Encode cancer subtypes as numeric labels
- Train an XGBoost classifier in a Scikit-learn pipeline
- Save the trained pipeline (
classifier_pipeline.joblib) - Load the model in a Streamlit dashboard:
- View performance metrics
- See top gene importances
- Select a sample and get predicted cancer type
Output
- ✅ Accuracy: ~85% on test data (varies by split)
- 🔬 Top genes shown by feature importance
- 🧠 Interactive Streamlit web app for exploration
 Medical Imaging
Medical Imaging